Projektjahr 2024
Core Spot® Manager
Mandantenfähige SaaS-Plattform für EU-Nachhaltigkeitsberichterstattung nach CSRD/ESRS mit granularem Berechtigungsmodell und automatisierter Provisioning-Pipeline von der Lizenzeingabe bis zum laufenden System. — Herstellerseite
Inhalt
Kontext
Die EU-Richtlinie CSRD verpflichtet Unternehmen, nach den ESRS-Standards strukturiert über Nachhaltigkeitsaspekte zu berichten. Der damit verbundene Aufwand ist erheblich: Unternehmen müssen eine doppelte Wesentlichkeitsanalyse durchführen, Stakeholder systematisch einbinden, ihre gesamte Wertschöpfungskette dokumentieren, Branchenklassifikationen zuordnen und hunderte regulatorischer Datenpunkte erfassen und auswerten. Der Core Spot Manager adressiert diese Komplexität als zentrale Plattform, die den gesamten Prozess von der Datenerhebung über die Wesentlichkeitsanalyse bis zur modulgesteuerten Berichterstellung abbildet.
Das System ist mandantenfähig konzipiert: Ein zentrales Backend verwaltet Regulierungstexte, Stammdaten und Lizenzen, während jeder Mandant eine vollständig isolierte Instanz mit eigener Datenhaltung, Suchinfrastruktur und Benutzerberechtigungen erhält. Mehrere lizenzierbare Fachmodule steuern den Funktionsumfang pro Mandant.
Umgesetzter Funktionsumfang (gegliedert, ohne reinen App-Rahmen wie Login- und Fehlerseiten):
- Accounts & Kontakte
- Account-Liste und -Details
- Geeignet für mehrstufige Unternehmensstrukturen
- Kontakt-Liste und -Details
- Wesentlichkeitsanalyse
- Übersicht; Zugriffskontrolle pro Analyse und Aspekt
- Longlist; Short-List
- Aspekt: Hinweise, manuelle Erfassung
- Auswirkungen, Abhängigkeiten, Risiken/Chancen (IDRO)
- Stakeholderbezug am Aspekt; Stakeholder-Umfrage
- Tasks & Kommentare am Aspekt; Bewertung
- Stakeholderanalyse
- Übersicht; Detailansicht mit Tabs
- Identifikation; Interessen/Anforderungen
- Einfluss; Betroffenheit; Ergebnis (Matrix/Quadranten)
- Einbindungen; Dokumente
- Wertschöpfungskette
- Übersicht; Identifikation
- Vorgelagerte, eigene und nachgelagerte Kette
- Dokumente
- Ziele & Maßnahmen
- Übersicht; Zielformulierung
- Verknüpfte Maßnahmen; Maßnahmenformulierung
- Weiterer Funktionsumfang
- Persönliche Daten
- Wirtschaftsjahre, Schwellenwerte, Bewertungsmaßstäbe
- Suche (Accounts, Kontakte, Stakeholder)
- Dashboard
- Aufgaben & Kommentare
- Perspektiven (rollenbasierte Module und Navigation)
- Versionshistorie; Hinweise bei paralleler Bearbeitung
- Produkte & Dienstleistungen: hierarchische Produkt-/Leistungsgruppen
Rolle & Verantwortung
Ich verantwortete die Gesamtarchitektur und entwarf die dreischichtige Systemlandschaft mit getrenntem Zentral- und Mandantensystem. Die zentrale Architekturentscheidung bestand darin, die eingesetzte Backend-Technologie, die ursprünglich für den Betrieb mit eigenem Frontend ausgelegt war, rein headless einzusetzen. Um eine sauber entkoppelte SPA-Architektur zu ermöglichen, baute ich eine vollständige REST- und GraphQL-API-Schicht auf, implementierte ein eigenständiges Authentifizierungssystem und konzipierte ein klassenbasiertes Berechtigungsmodell mit rund 100 Einzelberechtigungen über mehrere Fachmodule.
Neben der Architektur setzte ich beide Backend-Systeme auf Basis von Symfony um und entwarf die Container-Infrastruktur mit CI/CD-Pipelines und automatisierter Provisioning-Pipeline.
Im Frontend arbeitete ich eng mit einem spezialisierten UX-/Markup-Entwickler zusammen, der das HTML-Markup und die CSS-Strukturen lieferte. Die Migration in die Nuxt/Vue-Komponentenarchitektur, die funktionale Integration und die Anbindung an die API-Schicht verantwortete ich.
Fachlich arbeitete ich eng mit dem Business Analyst und Product Owner zusammen und überführte deren Anforderungen in Datenmodell und Systemarchitektur. Die End-to-End-Testinfrastruktur von den Build-Skripten über die Testdaten-Erstellung bis zur Selenium-Anbindung entstand vollständig unter meiner Verantwortung. Darüber hinaus verfasste ich die technische Entwicklerdokumentation und führte einen dritten Entwickler in Projektstruktur und Entwicklungsprozesse ein.
Technische Architektur
- Dreischichtige Architektur: ein zentrales Stammdaten-Backend, mandantenspezifische Backend-Instanzen und ein entkoppeltes SPA-Frontend — jede Schicht unabhängig wartbar und über klar definierte Schnittstellen verbunden
- Mandantenisolierung auf Instanzebene mit dedizierten Containern und Datenbanken pro Mandant, ergänzt durch mandantenübergreifende Shared Services für Suche, Caching und Message Queuing
- Geschützte REST-API-Schicht für die System-zu-System-Kommunikation zwischen Zentral- und Mandantensystem mit mandantenspezifischer Authentifizierung
- Duale API-Strategie im Mandantensystem: GraphQL für CRUD-Operationen auf Fachobjekte, REST für spezialisierte Endpunkte
- Asynchrone Prozessverarbeitung via RabbitMQ mit über zehn dedizierten Queues für E-Mail-Benachrichtigungen, Datenimporte, Suchindexierung und weitere Hintergrundprozesse
- Entitätsübergreifende Volltextsuche über OpenSearch mit Fuzzy-Matching und mandantenspezifischer Indexierung
- Automatisierte Mandantenbereitstellung über eine mehrstufige Provisioning-Pipeline: Lizenzvalidierung im Setup-Wizard, Job-Queue im Zentralsystem, Container-Build und Credentials-Rückmeldung im Kernsystem
- Klassenbasiertes Berechtigungssystem mit rund 100 Einzelberechtigungen, modulbasierter Lizenzsteuerung und automatisierter GraphQL-Endpunkt-Generierung aus den Berechtigungsdefinitionen
- Automatisierter Import regulatorischer Stammdaten aus heterogenen Quellen — ESRS-Verordnungstexte via zustandsbasiertem HTML-Parser, NACE-Wirtschaftszweige via XML, eCl@ss-Klassifizierungen via CSV
- Gecachte Stammdaten-Synchronisation zwischen Zentral- und Mandantensystem mit mandantenseitiger Überschreibungsmöglichkeit für dedizierte Fachmodule
- CI/CD-Pipeline mit statischer Analyse (PHPCS, ESLint), End-to-End-Tests über Codeception und Selenium sowie automatisiertem Plattform-Build der beteiligten Systemkomponenten in GitLab CI
Herausforderungen
Headless-Betrieb der eingesetzten Backend-Technologie: Die eingesetzte Backend-Technologie ist für den Betrieb mit eigenem Frontend ausgelegt; eine fertige API-Schicht für externe Frontends existierte nicht. Um eine sauber entkoppelte SPA-Architektur zu ermöglichen, entschied ich mich für einen rein headless betriebenen Ansatz. Das erforderte den vollständigen Aufbau einer eigenen REST- und GraphQL-API-Schicht, ein eigenständiges Authentifizierungssystem mit Brute-Force-Schutz und Session-Management sowie ein klassenbasiertes Berechtigungsmodell, das die API-Endpunkte automatisch aus den Berechtigungsdefinitionen generiert.
Regulatorischer Datenimport mit zustandsbasiertem Parser: Die offiziellen ESRS-Verordnungstexte der EU liegen als komplex verschachteltes HTML mit bis zu vier Tabellen-Verschachtelungsebenen, Anhängen und Fußnotenreferenzen vor. Um diesen Importprozess reproduzierbar zu automatisieren, entwickelte ich einen zustandsbasierten Parser mit mehrstufigem Node-Tracking, der die DOM-Struktur systematisch durchläuft und das Ergebnis in ein hierarchisches Datenmodell mit eigenständiger Fußnotenverwaltung überführt. Ergänzend entstanden spezialisierte Importe für die NACE-Wirtschaftszweige und das eCl@ss-Klassifizierungssystem.
Domänenkomplexität der doppelten Wesentlichkeitsanalyse: Die CSRD fordert eine parallele Bewertung von Unternehmensauswirkungen (Inside-Out) und finanziellen Risiken (Outside-In) über eine mehrstufige Hierarchie mit vier Bewertungsdimensionen, jeweils mit eigenen Skalen, Schwellenwerten und branchenspezifischen Vorschlägen. Um diese fachliche Dichte beherrschbar abzubilden, entwarf ich gemeinsam mit dem Business Analyst ein hierarchisches Datenmodell mit kaskadierender Ergebnisberechnung: Wird ein Kindknoten als wesentlich bewertet, propagiert das Ergebnis automatisch über Events bis zum Hauptknoten. Die resultierende Berechtigungsstruktur allein für den Wesentlichkeitsbereich umfasst über 30 granulare Einzelberechtigungen. Ergänzend implementierte ich eine asynchrone Fortschrittsermittlung für die gesamte Wesentlichkeitsanalyse, die bei jeder Änderung eines einzelnen Aspekts sowie bei Änderungen an Auswirkungen, Abhängigkeiten oder Risiken und Chancen automatisch im Hintergrund neu berechnet wird.
Mandantenisolierung und automatisiertes Provisioning: Jeder Mandant erhält eine vollständig isolierte Umgebung, gleichzeitig müssen Stammdaten und Regulierungstexte zentral gepflegt und an alle Instanzen verteilt werden. Um die Bereitstellung neuer Mandanten durchgängig zu automatisieren, implementierte ich eine Ende-zu-Ende-Pipeline vom Lizenzschlüssel im Onboarding-Wizard über die Job-Queue im Zentralsystem und den mehrstufigen Build-Prozess auf den Cloud-Nodes bis zum laufenden Container mit angepasster Konfiguration und automatischer Credentials-Rückmeldung.
Berechtigungsgranularität mit automatisierter Endpunkt-Generierung: Das Berechtigungssystem umfasst rund 100 klassenbasierte Einzelberechtigungen über mehrere Fachmodule, ergänzt durch eine zeitraumbasierte Modullizenzierung pro Mandant. Um den Pflegeaufwand gering zu halten, entwarf ich einen Prozess, der die GraphQL-Endpunkte automatisch aus den ACL-Definitionen generiert. Dadurch fließen Änderungen am Berechtigungsmodell vollautomatisch in die API-Schicht ein und steuern unmittelbar die verfügbaren Funktionen und Ansichten im Frontend. Neben diesen technischen Berechtigungen existieren ergänzend redaktionelle Zugriffskontrollen, mit denen Nutzer den Zugriff anderer Nutzer auf bestimmte Wesentlichkeitsanalysen und einzelne Aspekte einschränken können.
Bidirektionale Datenkonsistenz und Event-getriebene Kaskadierung: Die Modellierung komplexer Abhängigkeitsketten erforderte eine Architektur, die bidirektionale Updates ohne Seiteneffekte verarbeitet. Ich löste dies durch ein zentralisiertes State-Management in der Subscriber-Schicht, das sowohl die Stammdaten-Synchronisation als auch die kaskadierenden Berechnungen der Wesentlichkeitsanalyse stabil und performant steuert.
Weitere Herausforderungen: Über die beschriebenen Schwerpunkte hinaus adressierte die Plattform weitere technische und konzeptionelle Anforderungen wie übersetzbare Legendentexte, mandantenspezifische mehrsprachige Inhaltstexte, eine vollständige Versionshistorie für alle Entitäten, Warnmeldungen bei ungespeicherten Änderungen sowie Hinweise bei gleichzeitigem Bearbeiten eines Datensatzes durch mehrere Nutzer.
Ergebnis
Über einen Entwicklungszeitraum von 20 Monaten entstand eine technisch umfassende SaaS-Plattform mit rund 1.300 Commits. Die Kernfunktionalität war vollständig implementiert und funktionsfähig: doppelte Wesentlichkeitsanalyse mit IDRO-Bewertungsmodell, Stakeholder-Management mit Matrix-Visualisierung, Wertschöpfungsketten-Dokumentation, CRM-Integration sowie Account- und Kontaktverwaltung.
CI/CD-Pipelines, eine End-to-End-Testinfrastruktur mit automatisiertem Plattform-Build, Error-Tracking und eine Provisioning-Pipeline für neue Mandanten waren aufgebaut und im produktiven Einsatz. Rund zwei Drittel der Gesamtcommits verantwortete ich persönlich, von der initialen Architektur über die API-Schichten bis zur vollständigen Testinfrastruktur.
Das Projekt wurde pausiert, nachdem die EU den Geltungsbereich der CSRD-Berichtspflicht für KMUs eingeschränkt hatte und die primäre Zielgruppe nicht mehr unmittelbar betroffen war. Die gelieferte Plattform war zum Zeitpunkt der Pausierung technisch betriebsbereit und durch das lizenzbasierte Modulsystem gezielt erweiterbar.
Einblicke
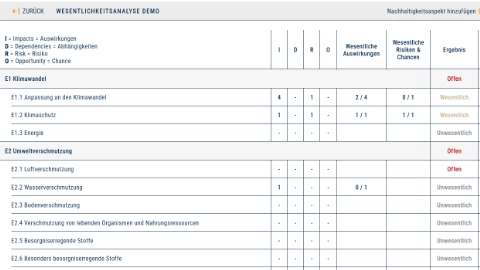
Übersicht aller Wesentlichkeitsaspekte mit granularer Zugriffskontrolle 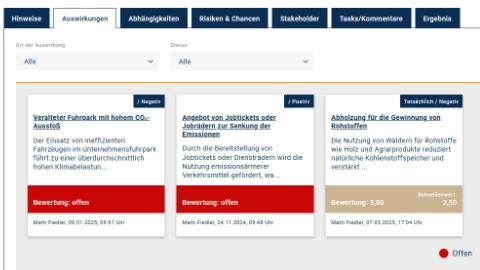
Verwaltung einzelner Wesentlichkeitsaspekte 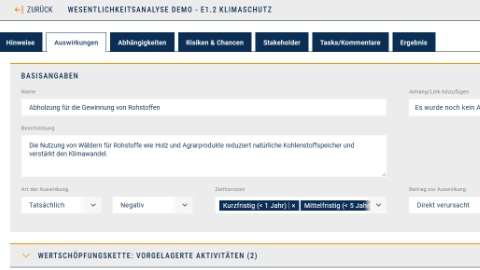
Bearbeitung der Auswirkungen einzelner Wesentlichkeitsaspekte 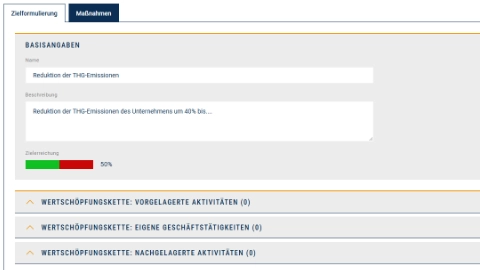
Verwaltung von Zielen und Maßnahmen 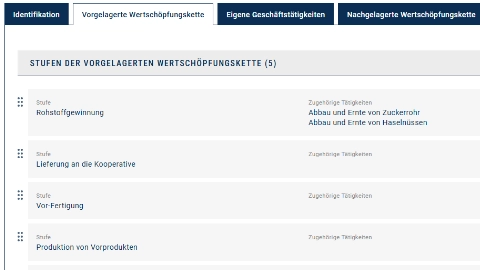
Verwaltung der Wertschöpfungskette 
Alternative Perspektiven für Nutzerrollen
Ähnliche Anforderungen
Bei vergleichbaren Fragestellungen genügen ein kurzer fachlicher Kontext und der Planungshorizont. Rückmeldungen erfolgen in der Regel innerhalb von 24 Stunden.